The Code Review is Dead, Long Live the Code Review!

AI code generation has transformed the way software engineers work, breaking something we took for granted: the code review. There is tension: on one hand, humans are responsible for verifying the quality of work AI produces; and on the other, if we review every pull request, the review becomes the bottleneck, and we forfeit much of the productivity gains of an AI-first development workflow. The traditional code review on every pull request is dying. That does not mean we should eliminate code review altogether.
Of course, it is impractical to conduct human code reviews on every pull request in these new AI workflows. The speed at which one person (let alone a whole team) can generate code using AI can far outpace the speed at which humans can review it. I still have an AI agent perform code reviews (more on that later), but for simplicity’s sake, from here on out, when I say “code review” without specifying, I mean “human code review”.
This piece is written for solo engineers or teams already operating in, or actively moving towards, an AI-first development workflow (hereafter, AI-first workflow). This probably also does not apply to high-assurance domains. It assumes you already believe in the value of AI code generation and that you are using some combination of spec-driven development (SDD) and test-driven development (TDD) to validate your business logic, preferably both. If this does not describe you, this piece might not apply to you.
If the traditional code review is transactional (meaning it centers on reviewing diffs for every change, i.e., per-PR), then what does the successor look like? I believe the right amount of code review is small and bounded, but it is not zero. To understand if, where, and how we should conduct code reviews, we need to analyze the benefits they historically provided and whether those benefits still apply in AI-first workflows.
Benefits of Code Reviews
Let me discuss the four benefits of code reviews that I think matter most. When talking about code reviews, perhaps the first thought that people have is verifying the correctness of business logic, and thereby reducing bugs. Transactional code reviews provided some incremental benefit in catching bugs, even if we believe the likelihood was low that code reviews would catch bugs in the pre-AI era. In pre-AI, there may have been many classes of bugs that code reviews could catch. Utilizing AI, many of those bugs can be prevented or caught autonomously. So the potential benefit in an AI-first workflow is limited to the set of bugs that the AI does not catch.
The second benefit is in good software architecture and patterns. In the past, if our system was well-architected and well-designed, it was easier for other human engineers to quickly reason about its intent and to confidently contribute soon after onboarding. They would be able to easily follow the patterns therein. Even if humans aren’t currently touching the code, we can still benefit from well-architected software systems when guiding AI coding agents through up-front spec definition. Furthermore, with well-architected software systems, our AI agents will be much more likely to code fewer mistakes, require fewer turns, and follow our patterns more easily, all of which lead to better software, creating a virtuous cycle.
The third benefit is a general understanding of the entire system and a deep understanding of specific parts. This can lead to emergent benefits when engineers realize potentially easy wins, improvements, and product ideas. I’ve seen it time and time again: if we enable and empower software engineers to provide ideas, they can contribute meaningfully to both software architecture improvements and product enhancements. This continues to apply in an AI-first workflow. A deep understanding of subsystems will enable software engineers to continue contributing ideas to the backlog.
The fourth benefit is primarily for teams: mentorship and team norms. Code reviews were always one of the best ways to provide cross-mentorship across the team and to solidify team norms. This was where we could detect anti-patterns, share patterns, and discuss/debate different opinions in conventions and norms. And in a world where the role of a software engineer is becoming more and more that of a software architect, these skills will be even more critical for every software engineer to do their job.
AI-First Assurance System
Now that we have discussed four key benefits of code reviews, let’s examine how AI changes the landscape with the first benefit. To match the speed and throughput of AI code generation, I rely heavily on what I’ll call an AI-first assurance system to establish confidence about code correctness, rather than on human effort. This system combines pre-codegen work (SDD and TDD phases) with post-codegen work through AI code review. By pushing much of the assurance work up front, I aim to reduce the number of errors that need to be caught later in the pipeline by AI and human code reviews.
SDD and TDD work together to give AI coding agents the best chance at writing bug-free code. Well-written specs can prevent AI agents from veering off the intended goals, and can prevent unstated assumptions from breaking code. TDD in a well-designed multi-agent system can help prevent the confirmation bias that creeps up in single-agent or code-first, write-tests-second methodologies. And then by adding a cross-model AI agent to perform code reviews on every pull request, I catch most issues arising from bias or hallucination that affect only one model. For example, I use Codex to review my Claude-generated code, and it has caught meaningful issues in every pull request since adding it to my pipeline. And these are issues that would have required human intervention to fix before deployment.
Each step in an AI-first assurance system filters out classes of bugs. But the cross-model review has a real limitation. Models do share some hallucinations and biases, so a cross-model review cannot detect bugs due to errors they both share. The bugs that remain then fall into one of two classes: (1) due to poorly written specifications and (2) due to errors common to both models. The first class is best addressed by writing higher quality specs, but some will still escape the AI-first assurance system. I’ll call all of these escaped bugs, regardless of the reason they escaped, residual bugs. It is with this context that I introduce the three new code review types I use in my workflow.
Three Code Review Types for AI-first Workflows
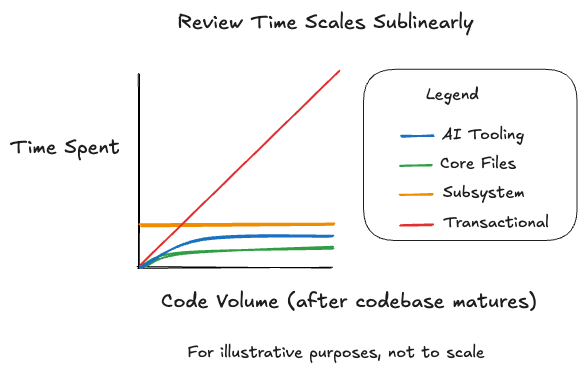
Given that my AI-first workflow can produce significantly more code than I could potentially review, I need to ensure that the number of code reviews scales sublinearly with the amount of code AI agents can generate. If we don’t, then as the amount of AI-generated code ramps up, code reviews will dominate our time, reducing the time we can produce value. But, for the benefits stated and why they still apply in an AI-first world, I don’t want the amount of my code reviews to be 0. With that in mind, I focus on three areas where I believe humans can have high-leverage impact with their increasingly precious time. I find that they are critical for me as a solo engineer, but I also believe they would be especially helpful for teams. Before I describe the three review types, here’s how they scale relative to transactional reviews, with the reasoning explained in each of their respective sections.
AI Tooling Code Review
This might be obvious, but I review all changes to the files that instruct my AI on how to develop and act. This includes CLAUDE.md/AGENTS.md files, skills, and agents. This is perhaps the highest-leverage code review, as the time I invest here has large ramifications on the quality of code that my AI system will produce. This is also where I can encode my conventions and quality checks. And for teams, this is where you can codify your team norms.
The review burden scales independently of the volume of code my AI-first workflow produces. Early on, when initially building out my pipeline, this required frequent manual review. But as the system stabilized, changes to AI tooling became increasingly infrequent. Right now, I make a handful of mostly small tweaks each week, with perhaps one larger enhancement. Likewise, I’d expect new teams to see some initial thrashing here that quickly stabilizes.
Core Files Code Review
These are the files that I feel are either core to the functioning of my software or are too important not to review. These are my data models, data validation schemas, security, and any prompts that I use in my product. AI tends to make generalized assumptions in these core areas, which contradicts how I want to tailor them to my specific use cases. I find that if I have these well thought out, it helps the LLM generate better code the first time, not only when extending the core files, but also in the business logic that depends upon them.
Scaling looks different here: on greenfield projects, my core files initially scaled linearly with the number of commits my AI-first workflow produces. This makes sense because my data models and validation schemas were new and I was adding them with almost every new feature. But as my core files stabilized, changes there became increasingly rare. The distribution of my commits shifted heavily toward building features upon my existing core files instead of modifying them. Over the last few months, I’ve had almost no commits to my data models and schemas in any given week, and the ones I’ve had have all been very small changes, which were very quick to review. The occasional new model or schema in the future might take a little bit more time, but it is worth the effort to get it right the first time.
The Periodic Subsystem Code Review
I divide my codebase into software subsystems, which I define as sets of files that frequently change together, often organized by business domains (e.g., Authentication and Token Management, User Connections and Management, Climate and Weather, Invitations & Onboarding). Then, periodically on a schedule, an agent submits a pull request indicating which subsystem to review that day (more details below).
While each code review is grouped by subsystem, I do not focus these reviews solely on software architecture. They are primarily intended for me to deeply read the code and to challenge the business logic therein. To help achieve this, the primary design principle is that the files within each subsystem are logically connected, as defined above. As a secondary design principle, I size them so that I can review them in 1-2 hours.
This is the one code review type whose cost remains constant no matter how much code AI generates. If I significantly increase the number of subsystems, then I may need to increase the number of reviews I do each week, but that’s not because of the volume of code; it’s because of how I organize the code.
How the Reviews Map to the Benefits
Let me discuss how each of the three reviews maps to each of the four benefits, based on my experience and through some extrapolation. I describe my first two types of code review together, then detail my third type of code review. I then summarize this in a table at the end of this section.
The first two types of code reviews share many of the same strengths and limitations of the transactional review because they operate on the same model: a change is made, and I read the diff, trying to understand if the diff met the original intent. AI tooling code reviews don’t contribute to code correctness and bug detection directly, and core files code reviews can only help in their narrow limited scope. They both contribute to good software architecture. Well-written skills files can help ensure that AI follows good architectural patterns, and core files provide a foundation for it to build upon, helping reduce drift from the desired software architecture. However, they are weak in providing system understanding. And they don’t provide many opportunities for mentoring or debating team norms, being limited to narrow parts of the codebase.
Now, let’s examine the benefits provided by the periodic subsystem review. A major advantage of reviewing code by subsystem is that it helps me review the code and logic holistically rather than transactionally. This holistic review process makes it easier to reason about the code and its interactions, helping me detect many of the residual bugs that may escape my AI-first assurance system. So, compared to transactional reviews, while I increase the time these residual bugs remain undetected in production, I also increase the likelihood of catching them. And the amount of time they remain undetected is practically limited by the design of the subsystem review. In my specific design, I will effectively review all subsystems about once every four months. This may seem long, but systems that don’t change often won’t introduce these residual bugs and won’t require a code review. (For a different bug class: bugs caused by external system changes wouldn’t be detected by transactional reviews either, and are best detected by other systems, such as through observability platforms and tooling.) Given these comparisons, the limited time spent on periodic subsystem reviews is more useful than the uncapped time spent on transactional reviews.
It also helps with the second benefit of good software architecture and patterns by organizing the code review holistically around a subsystem, making it easier for me to reason about the design, and to simultaneously review both (a) all individual flows within that subsystem and (b) its touchpoints to other subsystems. Further, even with well-written skills files and documents preventing drift up front, the AI coding agents still occasionally drift from my original intended software architecture and patterns over time. This is an opportunity to correct those drifts.
For the third benefit of improving general understanding of the overall system and deep understanding of parts, it clearly provides this understanding, perhaps more so than transactionally-based code reviews. For the fourth benefit, while this does not apply to me, this type of code review seems like a place where teams can have more meaningful cross-mentorship conversations and debates about team norms and conventions.
Implementation
So, how do I do this? Here, I share how I’ve implemented the three types of code reviews using my specific tools. You can adapt the guidance below to whatever systems and tools you use.
The first two code review types are easy. They’re still transactional, so I use traditional methods to ensure they capture my attention. I use a CODEOWNERS file to map out the files and directories that I consider AI agent infrastructure or core to the product. I then put in a branch protection rule on main with the following checked: (a) “Require a pull request before merging” and (b) “Require review from Code Owners”. This is where having a separate GitHub account for my Claude agent to submit pull requests is helpful. If Claude submits PRs as me, they will be auto-approved, bypassing the Code Owners protection. To ensure I’m not reviewing non-core code in my core file reviews, I move any non-core code out of those core files.
For the periodic subsystem code review, I created an async-reviews/ directory in my project root. It is seeded with an initial state.json that describes all of my software subsystems. Then I created a skill that scores each subsystem by the number of commits since the last review + the number of days since the last review. This system prioritizes subsystems with many commits but ensures that every subsystem will eventually be touched. I might tweak the scoring or frequency of code reviews if I find that it’s starving some subsystems. You could choose to do something more even, like a simple round-robin, or tweak the algorithm for your purposes.
This skill will then select the highest-scoring subsystem. It will update the last_reviewed_at date for that subsystem in async-reviews/state.json and open a PR with a body that enumerates all of the files in the winning subsystem. I then use Claude Routines (/schedule) to schedule that skill to run twice a week. When I am ready to read the review, I look in GitHub at the PR, read the files that it points to, and then open up GitHub issues for anything I see problematic. Once I am done, in one of my dev environments, I merge that PR in so that the system has the timestamp when that subsystem was last reviewed.
Closing Thoughts
Outside high-assurance domains, transactional code reviews often cost more in slowness than they add in value beyond what AI-first assurance systems already provide. That is why I no longer focus on transactional code reviews to catch bugs. Instead, my time is often better spent on improving the specifications and high-level architectural guidance. Together with periodic subsystem reviews, I mitigate the risk even further, bringing it to a level I am willing to accept.
I spend less than 4 hours a week reading code now (usually around 2-3). Furthermore, this system caps the time spent on code reviews, keeping it constant even if an AI-first workflow generates many more features, lines of code, commits, or PRs.
While I mostly spoke to my experience as a solo engineer, I think that these principles apply to teams even more so. If you are already doing something like this on your team, or you end up experimenting with this type of system, please let me know where it works for you and where it doesn’t.
AI capabilities are evolving quickly, and so will my practices. But the underlying principle that human time is even more precious now, and that it should be spent where AI cannot substitute, not where it can, is unlikely to change.